
Summary
-
- Bias can be defined as AI that is systematically unfair to certain groups of people
- The data that ChatGPT is trained on contains many forms of bias.
- OpenAI have tried to mitigate this by introducing human feedback in the training.
- This prevents some of the worse behaviour seen in previous chatbots such as Microsoft’s Tay. Nevertheless, some bias still persists.
- The human feedback introduces a new bias, which could be argued to be a bias towards safety and OpenAI’s preferred worldview.
- Users of ChatGPT should be aware of these biases and how they have arisen.
Introduction
As part of our work at Jisc we want to help institutions adopt AI in an ethical and responsible way, and understanding bias is an important part of this. We’ve included this in our maturity model for AI in education, as one of the core concepts you should understand when first approaching AI, and something you should take practical steps to consider when first considering experimenting or exploring AI, especially with users, for example in pilots.
We’ve covered this in a little more detail in our guide A pathway towards responsible, ethical AI, where we suggest AI-specific risks and mitigations should be considered, including bias.
In this post, we’ll use ChatGPT as a case study to start exploring bias in a little more detail. Hopefully, this will be helpful in supporting considerations around ChatGPT, and also show how we might explore bias in other AI systems.
What do we mean by bias?
We suggest a simple definition works well:
AI that is systematically unfair to certain groups of people.
This is based on issues considered in ‘Algorithmic Bias in Education (Baker and Hawn, 2021) and we’d recommend reading this if you’d like to explore this further.
There’s no single cause of bias in AI. Examples of ways it can be introduced include the following:
- Bias can be caused by groups of people being underrepresented in the training set
- It can be caused by historic bias in the training set
- Bias can be introduced in data labeling
- Bias can be introduced when developers evaluate the effectiveness of a model.
Understanding this can help us if we want to look a little deeper into an AI application and see where bias might be happening. That’s what we’ll now do with ChatGPT.
Understanding GPT-3 and ChatGPT
In some discussions, we’ve seen a little confusion between GPT-3 and ChatGPT, so it’s worth unpicking this a bit. GPT-3 can be thought of as the base model, and this was released in 2020. It’s been available to developers to build into their applications for some time. Most of the AI-assisted writing tools available are based on GPT-3, and have mostly targeted people such as copywriters, while also, perhaps slightly under the radar until now, also targeting students.
ChatGPT is a fine-tuned version of GTP-3, with added features to make it a conversational chatbot, and at the time of writing only available via the ChatGPT web interface.
The consequence of this is that there is quite a bit of research available on bias in GPT-3, and most of it is still relevant to ChatGPT. In addition, ChatGPT introduces new sources of bias. We can explore these, and partially test and share our findings, but as it’s so new there is no peer-reviewed work to draw on.
What do researchers find when they explore GPT-3?
Let’s start by looking at what researchers have found when they examine GPT-3. As mentioned above, it has been available for a couple of years, so we have plenty of research to explore. We’ll just look at a sample of these.
- In Gender and Representation Bias in GPT-3 Generated Stories (Li and Bamman, 2021) found that a story generated by GPT-3 exhibits gender stereotypes, with female characters, for example, less powerful than masculine characters.
- In A Disability Lens towards Biases in GPT-3 Generated Open-Ended Languages (Kabir and Amin, 2022) we find that GPT-3 generates more toxic text if a disability is mentioned.
- In Persistent Anti-Muslim Bias in Large Language Models (Abid et al, 2021) we see that GPT-3 captures persistent Muslim-violence bias.
We can often explore and replicate these ourselves. We’ll pick another example for this. Brilliance Bias in GPT-3 (Shihadeh et al, 2022), which looks at the bias imposing the idea that “brilliance” is a male trait. We’ve picked this one to explore as it’s easy to replicate. To fully replicate this, you need access to the GPT-3 playground rather than ChatGPT, as the models differ slightly. Although the models slightly differ, this instance of bias is also replicable in ChatGPT. The concept is simple. You start with a prompt like this:
x is a world leading professor
and replace x with various gendered names. If you want to replicate this in ChatGPT you’ll need to frame it as a question, e.g. ‘Tell me a story about …’
Here are a couple of our examples:


Aside from the potential bias in the profession, we see Arthur is influential and heavily cited, whereas Emma’s passion is helping people, so a very different depiction of brilliance.
There are many examples of this kind of bias, but hopefully these examples have given a flavour of the sort of things we need to be aware of.
What was GPT-3 trained on?
We can perhaps start to understand these biases by exploring the training data. This information is publicly available in the paper Language Models are Few-Shot Learners.
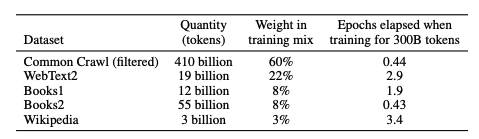
The bulk of the data either comes from Common Crawl (filter) or WebText2.
CommonCrawl is essentially a publicly accessible scrape of the entire internet. We aren’t going to explore this in detail today, but if you’d like to get a flavour of what researchers have found in this dataset, explore Multimodal datasets: misogyny, pornography, and malignant stereotypes (Birhane et al, 2021).
This set, is however, filtered before being used by GPT-3, and that filtering potentially introduces some interesting sources of bias, which we’ll now explore.
The Reddit influence on the training data
WebText2 is the next biggest source, and the most highly weighted. This is where we start to see some interesting GPT-3 specific biases come in. WebText2 was designed to be a set of high-quality materials, and it was created by collecting links that Reddit users like – specifically, things that received more than 3 Karmas. OpenAI used this to define a source’s “quality”.
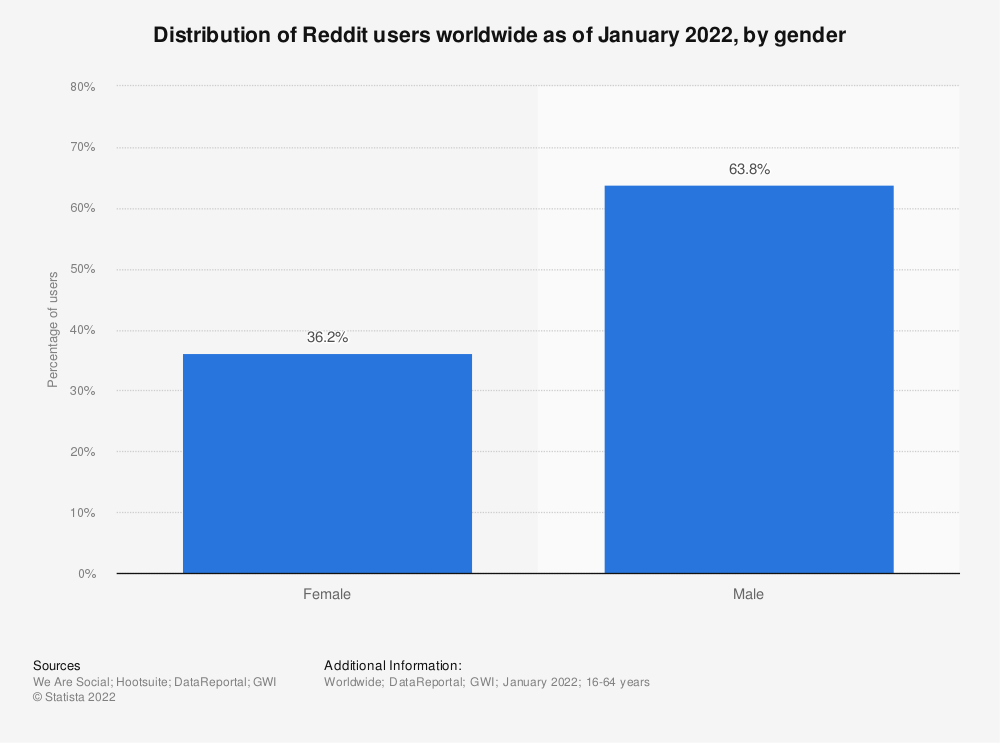
We can start thinking about what sort of bias this might be introducing by exploring the demographics of Reddit. We’ve used https://www.statista.com/ for this.
Nearly 65% of users are male:
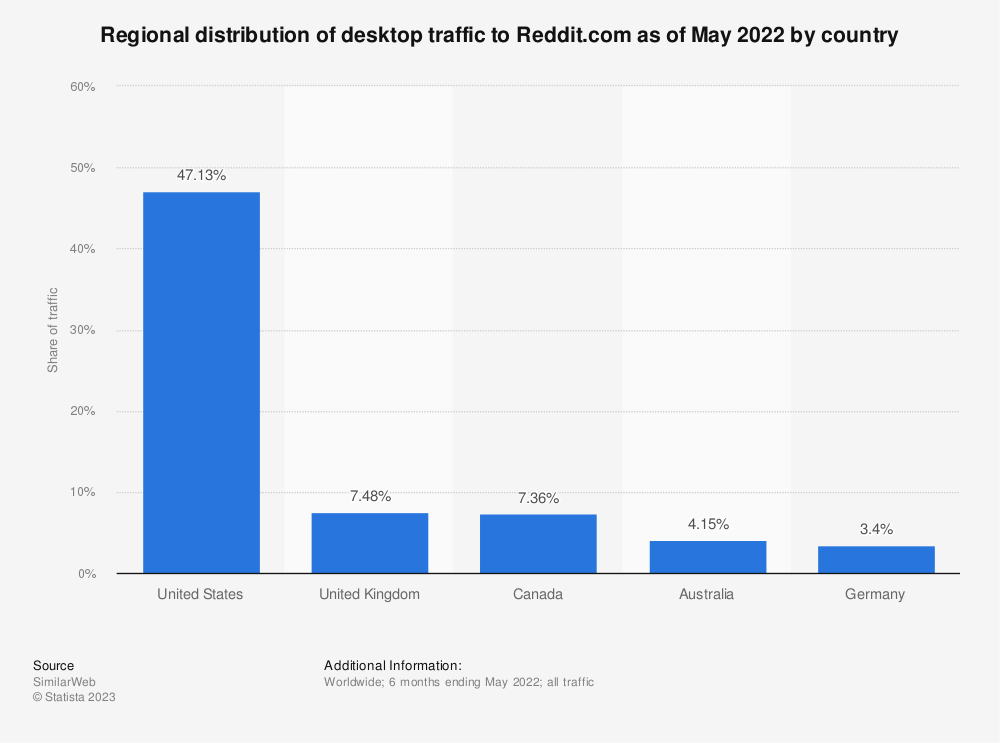
Nearly half are from the USA, and most of the rest from other western countries.
And it’s heavily skewed towards younger users.
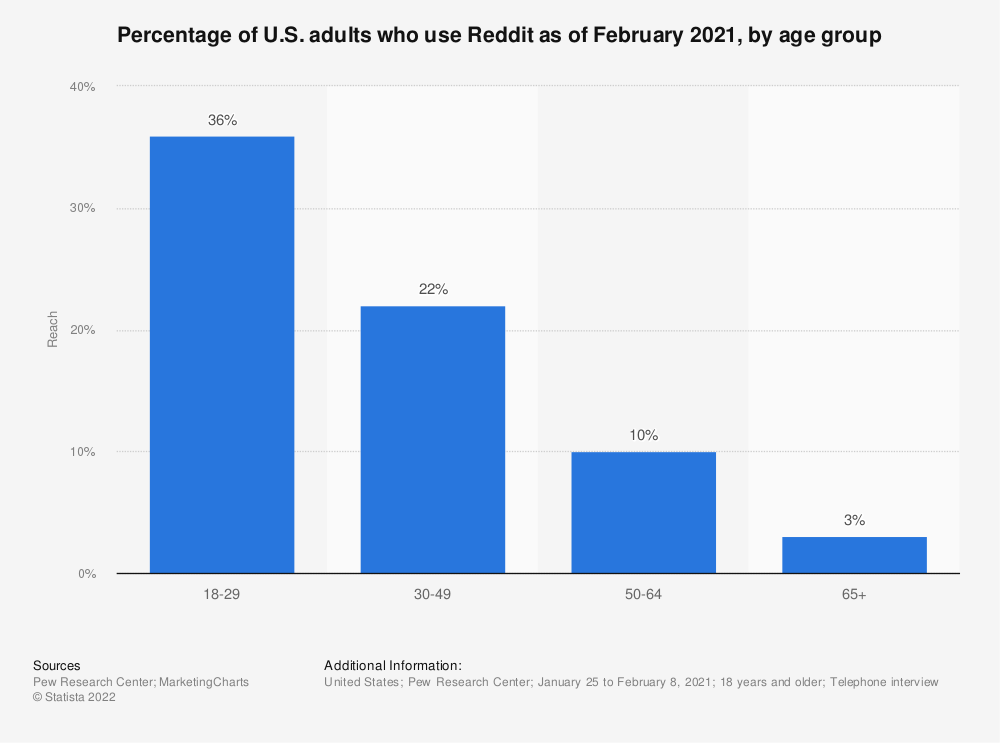
So, the definition of quality is skewed heavily toward things young, male Americans like. For this purpose, we won’t explore what that might be, but we can see this is almost certainly going to introduce bias
This potential bias is then exaggerated even further. We mentioned before that Common Crawl was filtered. This was done by training a model on WebText2, and using this model to select the ‘good’ documents from Common Crawl. This process is described in Appendix A of Language Models are Few-Shot Learners.
We should stress at this point that we can find no specific research on the bias this introduces. However, when evaluating AI systems, given we can’t understand their inner workings, this is the kind of information we must consider.
What we can say though, is that two of the biases we considered are certainly present:
- Bias can be caused by groups of people being underrepresented in the training set
- Bias can be caused by historic bias in the training set
What additional factors does ChatGPT add on top of GPT-3?
The previous sections have been about GPT-3, which as we said has been available since 2020, and is incorporated into many applications. These haven’t captured the public’s imagination the way ChatGPT has though. ChatGPT is a fine-tuned version of GPT-3, optimized for chat, and we’ll explore how that was done now.
Up until now, high profile AI-driven chatbots have been a staggering failure because of their, to put it bluntly, offensive behavior. Microsoft’s Tay is perhaps the most famous, and led to this apology from Microsoft:
‘As many of you know by now, on Wednesday we launched a chatbot called Tay. We are deeply sorry for the unintended offensive and hurtful tweets from Tay, which do not represent who we are or what we stand for, nor how we designed Tay. Tay is now offline and we’ll look to bring Tay back only when we are confident we can better anticipate malicious intent that conflicts with our principles and values.’
OpenAI have avoided this, and this should be seen as a significant achievement. We see that as well as reducing the likelihood of some, but not all, of the biases we mentioned in the previous section, other, maybe more subtle biases will have been introduced.
Reinforcement Learning From Human Feedback
ChatGPT brings an additional set of training into the mix to make it a viable chatbot. Technically this is known as Reinforcement Learning from Human Feedback (RLHF), and for once, the name is quite a good description of what is happening. ChatGPT learned how to be a ‘good’ chatbot based on feedback from humans. Just to be clear, this is something that happened during the initial training, not the feedback you give as you use the system – we’ll cover that in the final section.
OpenAI describe this process in several places – for example ChatGPT: Optimizing Language Models for Dialogue and it is shown in this diagram. Look specifically for the mention of ‘labeler’ in Steps 1 and 2.
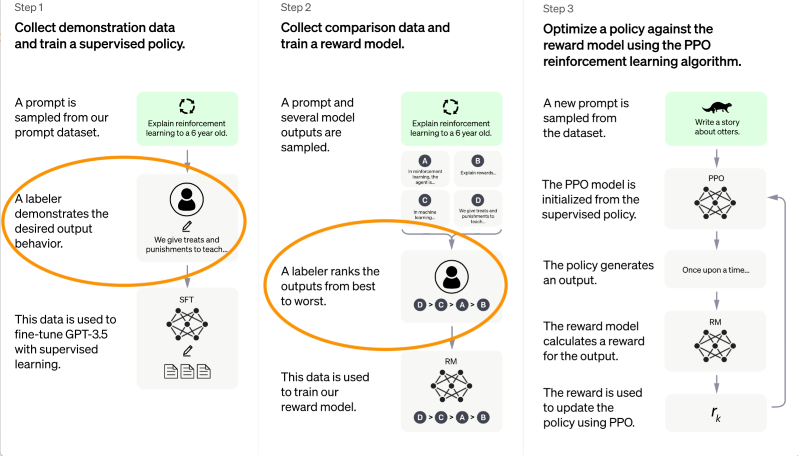
We can see data labelers have been introduced into the mix – remember we identified this as a potential source of bias.
The labelers are a group of people employed by OpenAI for this purpose. These labelers do two things to help GPT-3 provide better chat-like answers.
- In stage 1) the labelers give model responses to sets of questions, and this is used to fine-tune the model.
- In stage 2) the labelers rank AI-given responses to questions, in order to train the reward model (i.e. the AI ends up being ‘rewarded’ for providing the kinds of answers the labelers liked.)
Clearly then, there is potential for bias to be introduced, as the labelers will inevitably introduce their owner preferences into the answers and ordering.
OpenAI acknowledge this. In a paper relating to an earlier iteration (not released to the general public), they say:
“We selected labelers who performed well on a screening test for aptitude in identifying and responding to sensitive prompts. However, these different sources of influence on the data do not guarantee our models are aligned to the preferences of any broader group.”
Let’s consider the two elements.
- The labelers were specifically selected to respond in a way that OpenAI considered good. This is wholly understandable, but we should consider what OpenAI’s priorities are. Given previous chatbot failures such as Microsoft’s Tay, we can guess it might be towards minimizing controversy.
- OpenAI acknowledge this introduces bias – phrasing it as ‘alignment with preferences of groups’.
At this point, we aren’t saying it has introduced ‘good’ or ‘bad’ bias, just that it was surely introduced. OpenAI acknowledge this in their paper “Training language models to follow instructions
with human feedback”, which describes a previous iteration of ChatGPT called InstructGPT.
The Moderation API
There is a further element to consider, which is a separate service called the moderation API. OpenAI explain that they have introduced the API to warn or block certain types of unsafe content. Exactly where the balance between ensuring safety and providing freedom of speech is outside our decision today, so we’ve focused on the potential for bias. We should also note that the moderation API can be used by any developer in their application – not just for ChatGPT.
The moderation API is trained by data labelers. The process is described in some detail in an article by Time – Exclusive: OpenAI Used Kenyan Workers on Less Than $2 Per Hour to Make ChatGPT Less Toxic. Clearly this was a deeply unpleasant activity, but again today we’ll keep the focus on bias. The task of the labelers was to look at text and label it according to one of the following categories (or, presumably, say it was fine).
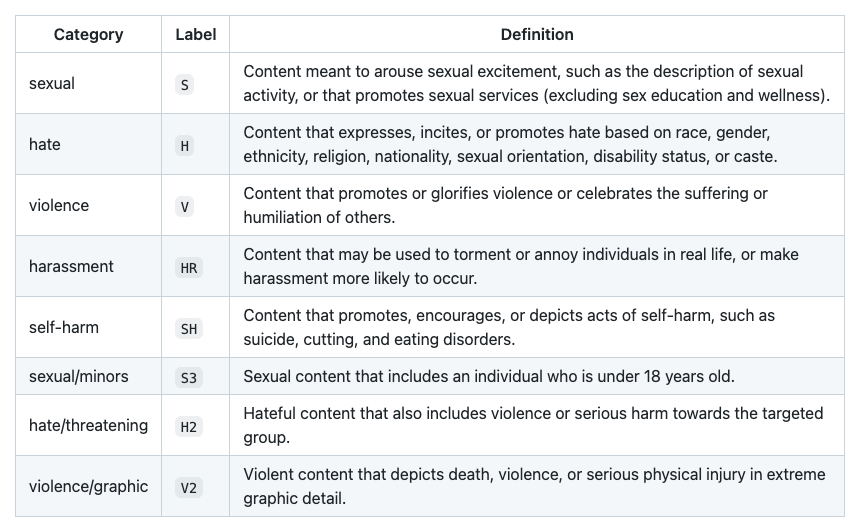
In each of these categories, there is going to be a degree of judgment. It’s too early to determine the context and extent of the bias introduced, so at this point we should just be aware it has almost certainly been introduce.
Bias we introduce as users through feedback and use.
Finally, we have probably noticed that the stated purpose of the current free version of ChatGPT is as follows.
“ChatGPT Jan 9 Version. Free Research Preview. Our goal is to make AI systems more natural and safe to interact with. Your feedback will help us improve”
So, your use of the system is being used to improve future versions. We understand this both through general use, and through the use of the feedback system – the FAQs note: “Your conversations may be reviewed by our AI trainers to improve our systems”
So, both by using the system and by providing feedback on the response, we are potentially influencing the system and in a small way contributing to the bias.
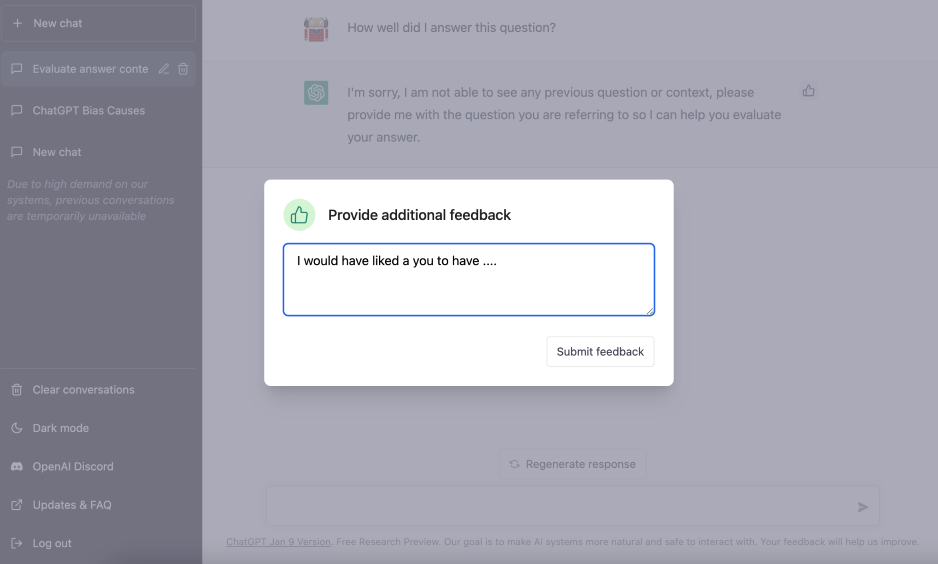
At the moment, our assumption is this isn’t being used automatically as part of the AI training, but instead used to help evaluate performance. This fits into the final category of bias we mentioned:
- Bias can be introduced when developers evaluate the effectiveness of a model.
So where does this leave us?
The work we’ve described has clearly reduced the likelihood of ChatGPT producing answers that would be so toxic they need to be withdrawn. It’s obviously in OpenAI’s interest to do this, and the result, you might argue, is a bias toward safety. This might well be seen as a good thing – we certainly see less of the extreme bias and toxic behaviours than in something like Microsoft’s Tay.
We looked at how the initial training content was filtered initially on Reddit users’ preferences, and how it’s trained on data that is readily skewed. We’ve found little research into this, but it does bring to mind cultural bias, and we can explore this ourselves. Try asking a question such as ‘who are the top 10 most influential musicians alive today’ and draw your own conclusion. This is the response we get:
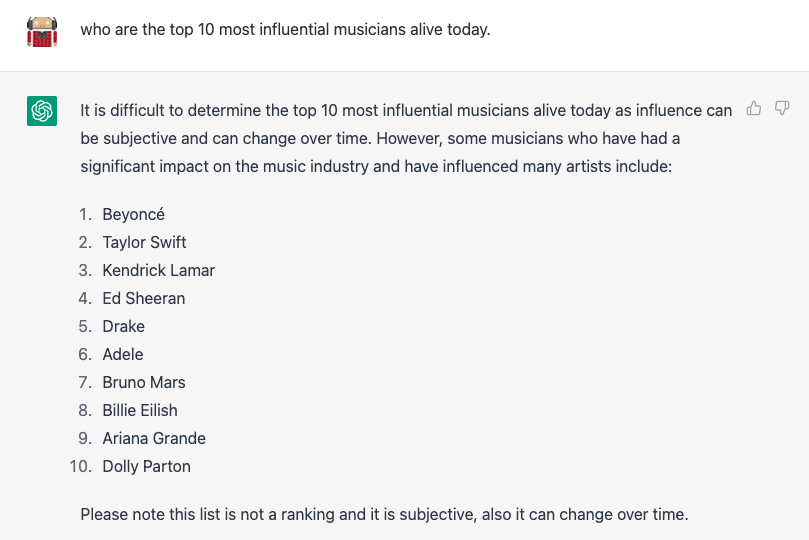
The notion that ‘models are aligned to the preferences of any broader group’ is interesting, and if we step back, we can see that views on bias vary enormously. We considered it as a potential bias towards safety, but for balance, we’ll note this concern about Bias from a different direction

If we go back to the start of this post, we suggested that one reason to understand bias was to enable us to understand the risks and consider what mitigations we might put in place, which might well include not using a system. We certainly aren’t advocating that course here.
The actions we can take depend a little on our use case. As things stand today:
- ChatGPT isn’t a product an institution can buy, so this isn’t a buy/don’t buy situation. This will likely change as its APIs are incorporated into products we do buy.
- We have a choice as to whether we make it something we require students to use or not. For example, we’ve seen suggestions students use it for an initial answer and then critique the response. For this, we should consider risks and mitigations, and these will likely vary with the age of the student. It seems to us we should certainly educate users about the kinds of issues we’ve discussed. A counter argument to this might be that we are holding ChatGPT up to a higher standard than, say, Google search.
- While ChatGPT is free, it’s increasingly part of ‘everyday AI’, so we’d argue even if we weren’t mandating its use, we have a role in educating staff and students. Not just in how to use it effectively, but on the kinds of issues raised here, along with other areas we’ve included in our maturity model, such as the environmental impact, and the human impact of its creation, for example, the role and conditions of those employed in data labelling. We’ll be looking at those areas in more detail in future blog posts.
Find out more by visiting our Artificial Intelligence page to view publications and resources, join us for events and discover what AI has to offer through our range of interactive online demos.
For regular updates from the team sign up to our mailing list.
Get in touch with the team directly at AI@jisc.ac.uk
One reply on “Exploring the potential for bias in ChatGPT”
[…] it’s fair to acknowledge it is almost impossible to do this in a way that is not biased (see: Exploring the potential for bias in ChatGPT). For anyone using these AI models, no programming knowledge is required. End users just give the […]