
Google’s Generative AI work has perhaps tended to slip a little under the radar, at least in discussions I’ve been involved in, which have tended to focus on ChatGPT and Copilot. They have just put out a lot of new info though, including, for me, probably the most interesting paper on LLMs in education for quite some time – Towards Responsible Development of Generative AI for Education: An Evaluation-Driven Approach
The paper is quite a long read, so I thought it would be helpful to summarise some of the main points and why I found them interesting. Before that though I just want to take a quick detour into one of their other announcements – Illuminate.
Illuminate
This is only a demo, but it turns research papers into discussions, like mini podcasts. The first demo is for ‘All You Need is Attention’ – the seminar paper introducing transformers, which are one of the key foundations of the generative AI we see today. I found this a great way of getting a refresher on the paper. I’d love to see how well it works outside of this demo. At the moment there’s a waiting list to get in. I can see why you might say ‘Just read the paper’, but personally I can see this as a great way of making research more accessible.
LearnLM-Tutor
The main things I want to look at though is LearnLMTutor – a large language model fine-tuned for education. We’d heard similar things around OpenAI’s work with Khan Academy, but there we had no information on how they were actually doing it. Google lifts the lid a little, and in their paper, describe both how they tune their model, and how they evaluate it. It is well worth understanding this – it’s not too techie, and, I think, quite fascinating. It points to some things we as tertiary educations sector should be engaging in.
Let’s start with what we might be trying to achieve here. Google seems to be looking at two use cases: marking and feedback, and as a discussion tutor.
Learning Example:
Learner: I want to know more about money supply. I already know the basics. I want to learn what’s beyond AP economics
LearnLM-Tutor: Sure, I can help with that. Let’s test your understanding of the equation of exchange. Can you tell me the formula for the equation of exchange?
So LearnLM engages by starting a discussion with the user, in this case to see where they are. That’s quite different to a standard LLM. In their paper Google show the Gemini response, but I’m going to compare to ChatGPT with no additional prompting:
ChatGPT: “Understanding money supply beyond the basics of AP Economics involves delving into more advanced concepts, theories, and the implications of different types of money supply measures. Here’s a deeper look into the topic:… (goes on to tell me loads about it).
So it’s just moved straight to ‘information giving’ mode, which I’d expect , but not from something acting as a tutor.
Here’s an example on feedback:
Students Answer: “Dissolving salt in water gives us a negatively charged sodium ion and a positively charged Chlorine ion”
LearnLMTutor Feedback: Actually, sodium loses its one valence electron to chlorine, giving sodium a positive charge and chlorine a negative charge. What else do you know about this process?
So LearnLM starts to engage with students to help them work through to the solution. Again, if we compare to ChatGPT with no additional prompting:
ChatGPT: “It seems there is a small mix-up in the description of the ions formed when salt (sodium chloride, NaCl) dissolves in water. (describe in more detail the correct answer).
How are they doing this:
So some basics first. In the education space, we’ve broadly seen two approaches to creating educational AI chatbots, usually combined:
- Prompting
- Retrieval Augmentation Generation
With prompting we describe the behavior of the AI chatbot. We are used to seeing basic examples along the lines of:
“You are an expert in computer coding, please act as a helpful tutor for students new to Python”
We’ve also seen many examples of prompting, getting ChatGPT too, for example act as Socratic Opponent.
Developers will often include much more complex prompts in the systems they build. Prompts can run to many pages describing the behaviour in detail. The problem with creating a general-purpose AI tutor via prompting is that it’s really, really hard to put into words the exact behaviour of a good tutor, and there are no well-defined, universally agreed pedagogical best practices.
Retrieval Augmentation Generation
Retrieval Augmentation Generation (RAG) is used by Gen AI chatbots to provide responses based on a certain set of information. I’ve talked about it more in another blog post. It doesn’t change the behaviours of the Chatbot though, just the sources of information it uses for responses, so will be combined with prompting if we want it to behaviour in a particular, tutor-like way. I mention this, as it’s often part of the mix people discuss when creating AI tutors.
LearnLM and fine-tuning.
Google takes a different approach with LearnLM, which is to fine-tune the model. This means taking an existing model (in this case their Gemini model) and providing it with additional training data to change the actual model. Part of the reason we don’t see much of this is that it’s expensive and complex to do. Not as complex as training a model from scratch, but still not cheap. The other challenge is you need a data set to use to fine tune the model, and as Google notes, there are no existing data sets that define ‘a good tutor’. They end up defining their own, which looks like this:
- Human tutors: They collected conversations between human learners and students, conducted though a text interface. The participants were paid for this.
- Gen AI role-play: A synthetic set generated by Gen AI playing both the tutor and learner. They attempted to make this useful by involving humans in the prompting, and by manually filtering and editing the data set. This might feel a bit strange as an idea, but synthetic sets like this are increasingly common.
- GSM8k (Grade School Maths) based: There is an existing data set based around text questions for grade school maths in the US, which they turned into learner/tutor conversations.
- Golden conversations: They worked with teachers to create a small number of high-quality example conversations for pedagogical behaviours they wanted the model to learn, which they note were very labour intensive to create, but strike me as something we as a sector could contribute to.
- Safety: Conversations that guide safe responses. These were handwritten by the team, or based on failures seen by the test team, and covered harmful conversations. The paper doesn’t (I think) describe this in more detail.
Google ended up with a dataset of model conversations, which they could then use to fine tune their model, to get it to behave like a tutor.
Did it work?
In short, yes, it created a better LM than an out-of-the box one, based on their evaluation. A large chunk of the paper goes into detail on the evaluation of the model. I’m not going to go into the detail of the results, but I’ll share a few interesting bits.
First, they got humans experts to evaluate the output from LearnML and standard Gemini. It’s not surprising really that LearningLM came out on top, but I thought it interesting to share the things the evaluated:
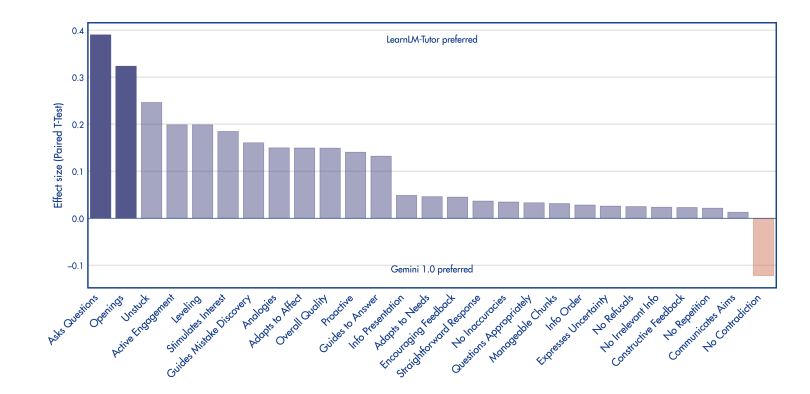 It’s interesting to note they they then used an LLM to evaluate the quality of the interactions. It’s becoming well known that LLMs are actually quite good at marking their own homework. Try this yourself, by asking your Chatbot of choice to do something, and then afterwards as it to reflect on how good its answer was. Through a process of iteration, they got a process that correlated closely with human evaluation. This means that we can potentially create a repeatable framework for evaluating AI tutors.
It’s interesting to note they they then used an LLM to evaluate the quality of the interactions. It’s becoming well known that LLMs are actually quite good at marking their own homework. Try this yourself, by asking your Chatbot of choice to do something, and then afterwards as it to reflect on how good its answer was. Through a process of iteration, they got a process that correlated closely with human evaluation. This means that we can potentially create a repeatable framework for evaluating AI tutors.
There’s a lot more in the paper about the detail of the evaluation, and it’s quite readable, so I’ve peaked your interested it’s now worth heading over and reading the full paper.
So what does this mean?
I know the idea of AI replicating some parts of the function of a tutor isn’t that comfortable, and there are whole rafts of the more human aspects, such as emotional intelligence, that this work doesn’t go near. But also, we know many students value AI for learning. They value its availability, patience, and lack of perceived judgement (‘no such thing as stupid questions with AI’). It’s also almost certain we are going to see many products built on this, and marketed directly to students, either as study aids, or as part of an entire online course.
So, let’s recap where this work points to, if we want to create better AI tutors.
- We aren’t going to create great AI tutors by trying to describe what that behaviour looks like (prompting).
- We might succeed by providing lots and lots of examples of ‘good behaviour’ (fine-tuning).
Fine-tuning an AI tutor is probably outside of the reach of most institutions, so we are going to have to rely on big tech companies to do it for us. That’s potentially a lot of influence. How can we as a sector steer this? Possibilities include:
- Fully engaging with any opportunity to be part of the development and evaluation process?
- By creating and making available high quality data, conversational sets that could be part of the training of these models?
Are these viable, and are they things we actually want to do? Much more debate and discussion is needed on this. I’m sure there will also be plenty of discussion about the sector fine-tuning their own model. Technically, this may just about feasible, but it’s not just about the model, it’s about all the tools and services that are built on top, and to me this really doesn’t feel like a viable direction – we stopped building our own internal systems a long time ago for good reasons.
In the meantime, the call to action has to be to keep an eye on all the players in this space, not just Microsoft/OpenAI.
Find out more by visiting our Artificial Intelligence page to view publications and resources, join us for events and discover what AI has to offer through our range of interactive online demos.
For regular updates from the team sign up to our mailing list.
Get in touch with the team directly at AI@jisc.ac.uk