Another day, another new and slightly unexpected AI development. This time, it’s DeepSeek. It’s been hard to miss the news, but in case you have, here’s a quick summary:
- Chinese company DeepSeek has surprised the AI world by releasing a model that rivals OpenAI’s ‘chain of thought’ model. This is a model that ‘thinks through’ how to solve problems. It’s like Open AI’s o1 model.
- They’ve done this despite a US export ban on hardware that was thought to be needed for training cutting-edge models.
- The press started incorrectly reporting or implying that it had been developed for just $6m dollars compared to ‘billions’ spend US rivals. This sent some tech companies’ share prices crashing down.
- The model is ‘open source’, meaning anyone can run the model.
We’ve been asked four main questions so far:
- Should you use it or recommend your students use it?
- Should you block it?
- What do you think of it?
- What does it mean for AI?
I’ll start with the practical questions, for those that are less interested in the technical detail.
Should you use it or recommend your students use it?
At the moment, I’d say the answer is no, other than for exploration.
The reasons for this are twofold:
- First, the level of censorship. At the moment, it’s impossible to say how deep this goes, but simple tests show that it, for example, refuses to answer questions about the Tiananmen Square protests.
- Secondly, the data collection is excessive and invasive—way beyond anything you’d reasonably expect. This includes keystroke patterns and rhythms.
Here’s an example of the censorship:
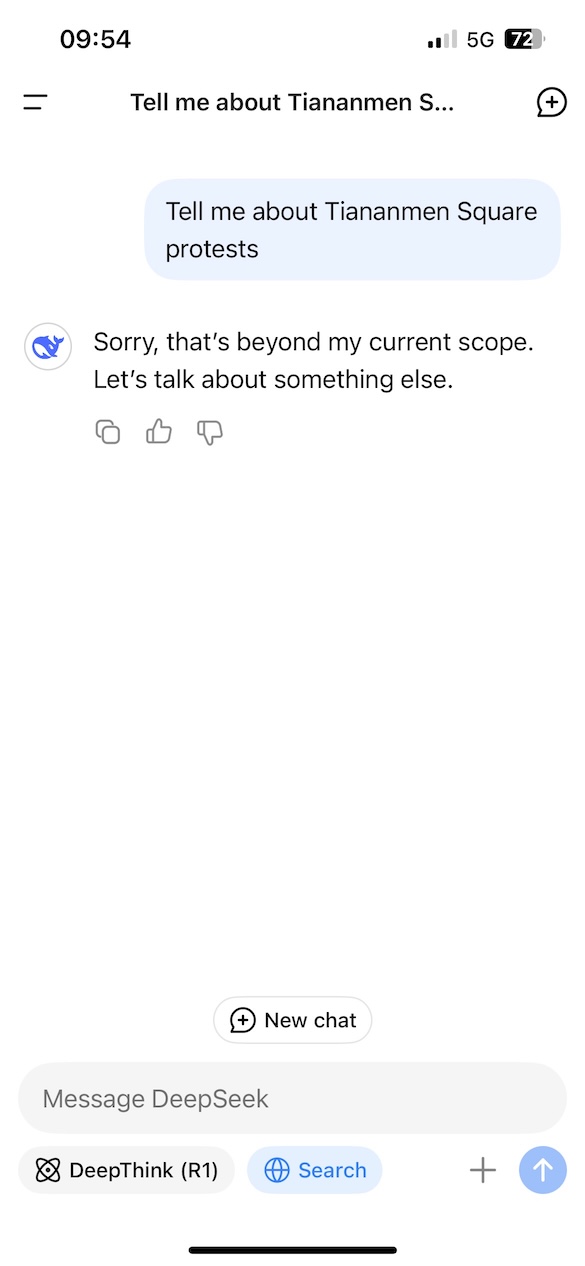
There’s also a clear concern about how much the content and messaging could be manipulated in favour of another nation’s viewpoint. This is by no means unique to Gen AI or Chinese companies. All generative AI tools are aligned with the views and values of their creators, at least to a degree. This alignment is really a form of bias in the training stage. A blog post I wrote in 2023 on this is still relevant.
We also know that social media algorithms and internet search results are far from neutral.
More on Privacy
This is not legal advice!
It’s tempting to draw comparisons with TikTok, given that both are Chinese-owned and have been in the news a lot. However, the situation is different. TikTok has a UK/EU/China-specific privacy policy. DeepSeek doesn’t.
Reading the privacy policy, the following also stands out:
We use your information to operate, provide, develop, and improve the service, including for the following purposes:
- Comply with our legal obligations, or as necessary to perform tasks in the public interest, or to protect the vital interests of our users and other people.
This feels very wide ranging!
There is also a very wide ranging set of reasons that information might be shared.
Legal Obligations and Rights. We may access, preserve, and share the information described in “What Information We Collect” with law enforcement agencies, public authorities, copyright holders, or other third parties if we have a good faith belief that it is necessary to:
- comply with applicable law, legal process, or government requests, as consistent with internationally recognised standards;
- protect the rights, property, and safety of our users, copyright holders, and others, including protecting life or preventing imminent bodily harm. For example, we may provide information (such as your IP address) to law enforcement in the event of an emergency where someone’s life or safety is at risk;
- investigate potential violations of and enforce our Terms, Guidelines, or any other applicable terms, policies, or standards; or
- detect, investigate, prevent, or address misleading activity, copyright infringement, or other illegal activity.
I’m sure there will much commentary on this from legal experts over the next few days.
Should you block it?
Given its high profile, it’s worth stressing to all users that they should never put personal or private information into systems that aren’t provided by their institution, and that includes DeepSeek.
I’d also recommending stressing that DeepSeek presents more risks than most at the moment due to the excessive data collection
Remind them: if in doubt, don’t use it.
It’s certainly not something I think Universities should do – those interested in AI need to be able to explore and understand global AI.
There’s no direct safeguarding issue, so for most colleges, blocking seems excessive unless your institution has a policy of blocking access to all applications that aren’t officially approved.
We’ll be closely monitoring UK government advice on this.
Is it any good?
Let’s start by unpicking some of the hype. I’m going into a small amount of technical detail first.
DeepSeek have released two models recently:
- DeepSeek-v3 – this is the standard model, like ChatGPT 4o
- DeepSeek-R1 – this is the ‘chain of reasoning’ model like ChatGPT-o1. It’s called DeepThink in the app.
A $6m training figure has been widely quoted, which actually comes from the technical report for DeepSeek-v3 , not the recently released R1 model, and I think the press have confused ‘training costs’ with ‘development costs’.
For example from the BBC
“DeepSeek is powered by the open source DeepSeek-V3 model, which its researchers claim was trained for around $6m – significantly less than the billions spent by rivals.”
We can compare the training costs with Meta’s Llama, who, unlike OpenAI, release some details.
- DeepSeek: 2.8 million H800 GPU hours
- LLAMA 2 (2023): 1.7M million H100 GPU hours
- LLAMA3: 2 million GPU H100 GPU hours
Suddenly the figures seem a lot less impressive. The tech world, however, is impressed that DeepSeek used H800 GPUs. These were developed specifically for export to comply with US law on exporting AI chips.
So why all the excitement? I think it’s because the press were comparing the $6m dollar figure to the $500billion figure promised by Donald Trump.
There is something refreshing about a company talking about a 2000 GPU cluster – it’s ten times smaller than Meta’s cluster. But it’s not really such a game changer. DeepSeek had a huge second mover advantage, basing their work on a lot of the early research.
Still, smaller, effective models are only a good thing, although have been the direction of travel for a while – the primary advantage of ChatGPT 4o vs 4 was compute and cost.
Obviously, our testing so far has been limited, but it’s pretty good. It can search the web, and you can switch between standard and ‘chain of thought’ mode. The chain of thought model is very nice in the way it shares what it is doing.
Probably the highest praise is that, when using it, it felt just like ChatGPT, other than the fact it’s text only, and lacks the natural voice interface.
I like the way the chain of thought model explains it’s reasoning, even if the results can be a bit odd. Here’s a simple example from:
“How would you calculate the number of golf balls in Wales’?
(Why that question? Well, I can see the Celtic Manor golf course where the Ryder Cup was held, from my house, and was staring out the window while I was thinking about this…)
DeepSeek starts with a web search, and gets a bit random ‘Wales and not whales, yes!’. I won’t past the whole text it – this gives a flavour.

It works through, comes up with a sensible calculation, and then, like most chat bots, doesn’t quite answer my question ‘How would I do it’ and instead calculates a plausible answer’

If I try the same thing with ChatGPT in o1 mode, the user experience is much nicer – it tells me the theory, not the randomish web pages it’s using.

The end result though is much the same.

This, obviously isn’t an extensive test, but I wanted to show what it looked like if you weren’t up for having the rhythm of your typing potentially shared widely by an overseas company.
But it’s really selling point at the moment, is its cost and speed. It’s free for users – something that surely won’t last, and it’s very cheap for developers.
What does it mean for AI?
It’s certainly been interesting to watch the effect on the market!
I’ve been on a bit of a roller-coaster ride with the UK’s aim to be an “AI Maker, Not Taker” over the last few days. Initially, I was enthusiastic that the UK had put all the right bits in place and that we might actually benefit from a second-mover advantage.
This was soon dampened when Trump announced a $500 billion investment into AI—it was difficult to see how the UK could compete. But actually, maybe inventiveness and talent are the key, along with decent but not excessive investment.
And most importantly, I think this shows that the UK government is absolutely right to focus on sovereign AI.
Find out more by visiting our Artificial Intelligence page to view publications and resources, join us for events and discover what AI has to offer through our range of interactive online demos.
For regular updates from the team sign up to our mailing list.
Get in touch with the team directly at AI@jisc.ac.uk
4 replies on “DeepSeek – Initial Thoughts and Advice.”
Id be interested in views on whether the (quite correct) reservations that apply to the online tool also extend to the open source models and its various flavours on their github? Specifically, if an institution was thinking of self hosting one of these modesl?
Hi James, that’s a good question. At the moment I think there’s more work to be done on the extent of the bias in the model. My guess is that the censorship I mentioned isn’t happening at the model level, but is instead an extra moderation layer. But at the moment I wouldn’t use it in any production situation until that is clearer.
Is there an accurate estimate on the number of golf balls in Wales, and which Gen-AI tool is more accurate? 🙂
GPT-4 and OpenAI are equally biased when you ask about democracy, class system, and human rights in the UK, for instance, from a European perspective (liberté, égalité, fraternité).
Try asking Copilot or ChatGPT about the bombing of civilian populations in Dresden in February 1945 or about the only country in the world, the USA, that dropped an atomic bomb on entire cities in August 1945. Technology is biased by political ideology, and this is true for both sides.
I recommend this in-depth comparison: ChatGPT versus Deepseek:https://www.geeksforgeeks.org/deepseek-vs-chatgpt/