Artificial intelligence (AI) is rapidly transforming the way we live, work, and interact with the world. From education and healthcare to business and media, AI is now embedded in many of society’s most critical systems. But as its influence grows, so do the ethical questions. Particularly around who are the beneficiaries of the technology? who does it empower? who does it disempower? and how can we maximise its benefits whilst minimising the negative side effects of AI?
Diversity & Inclusion
One of the ethical concerns about AI systems is around diversity and inclusion. AI systems learn from data, and the data used is reflective of our society, the world, our patterns, thought processes and behaviours. Our world isn’t perfect and so a lot of the data isn’t, it often includes the flaws and inequalities of the world around us. That means the biases, inequalities, and blind spots in society can and often do become ingrained into AI.
Bias in AI is the digital reflection of long standing institutional and historical power structures. The data that trains AI is shaped by centuries of colonialism and capitalist interests and frameworks, all of which have excluded or misrepresented many communities. Much of the world’s data infrastructure, as well as the development of AI systems, is dominated by a small number of powerful organisations, largely based in Silicon Valley and other Western hubs were leadership and decision making remain dominated by a narrow demographic, which lacks the diversity and representation of much of society’s communities.
These companies not only control the datasets but also the tools, platforms, and economic models driving AI innovation. In this landscape, systems are often built for scale and profit, rather than for equity, cultural understanding, or social justice. Without intervention, these forces risk continuing to embed and amplify historical inequalities in the technologies our society relies on.
When AI systems fail to reflect human diversity, they don’t just make mistakes, they exclude. This exclusion can limit how certain communities are seen, represented, or even served by technology. This blog will explore why diversity and inclusion in AI is essential. We’ll examine how these issues show up in AI today, the consequences they carry, and what steps we can take to build a fairer, more inclusive AI future.
Bias in AI Systems
One of the concerns in AI today is how it absorbs and amplifies existing biases, especially around race, gender, and appearance. This is particularly noticeable in image generation tools. From my own investigation using these platforms, I found the outputs consistently leaned toward stereotypical representations, often favouring lighter skin tones, Eurocentric features, and traditionally gendered appearances. Even without specific prompts, the models tended to default to western features. When I asked for images of a “Black woman” or “South Asian man,” the results were often inconsistent, less refined, or lower in quality.
Investigations have shown that these kind of disparities in outputs come from the class imbalances within the training data, meaning that the model is essentially reflecting the uneven representation it encounters during training. Put simply, if the internet offers more images of a particular demographic or stereotype, the model mirrors that imbalance, not by intention, but by design.
These patterns are also backed by data. Research around the makeup of data sets used for image generation models found that AI image models like Stable Diffusion, DALL-E and ChatGPT 4o, which are trained on massive internet collections have inclined data sets.
Take the examples below, these showcase OpenAI and their image generation models training data across the class distributions of race, gender and skin tone.
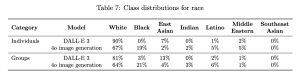
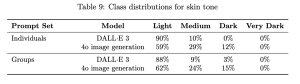
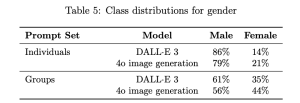
While OpenAI’s new image generation model does demonstrate incremental progress in addressing representation gaps, both models continue to disproportionately favour male, white, and light skinned outputs. These imbalances are not just statistical accidents; they mirror the biases in data and model training that must be addressed.
In other words, the raw training data itself reflects real world imbalances (e.g. more male scientists, more female nurses). These web-based datasets lack diversity, and models learn and produce outputs based off the limited perspectives. This kind of bias isn’t just visual, it affects how people are seen, categorised, and treated by AI systems. This can be problematic when AI is used in areas such as job discrimination, in justice and policing, decision making and education. When certain groups or communities are always prioritised or missed, others are made less visible or more visible, leading to deeper issues of exclusion and inequality across digital platforms.
Notably, it can also be challenging fighting against these biases. Mitigating bias in AI is a difficult task because there is often not enough data from underrepresented groups, it can be difficult to gather data for small or privacy sensitive populations, such as indigenous languages or vulnerable, or impaired users. This means AI models don’t learn well about them and can make unfair mistakes.
This occurs because models tend to focus more on the majority patterns, which leads to unfair or inaccurate results for less-represented people. It’s also difficult to define and measure fairness, since it varies by context and often involves trade-offs with performance of the systems. Addressing data bias manually requires complex techniques like data balancing, careful model training, and ongoing evaluation none of which are straightforward and quick.
Data bias in, bias out.
These result of these imbalances is that if we have this type of data going in, as end users, we will have this type of skewed data being returned to us. The consequences of these outputs can differ across context. From a media perspective we can see how our images in the world incline towards a certain appearance, reinforcing stereotypes and limiting the spectrum of visibility for underrepresented groups. This not only impacts how people see themselves reflected in technology but also influences perceptions at large.
In education it can be using systems which do not cater for diverse learners or consider issues such as digital poverty. As AI becomes more embedded in digital learning platforms, the risk is that subtle biases start to shape educational experiences for minoritised students, particularly those from underrepresented communities across the UK.
In the context of the job market, it can be in the form of discrimination, organisations adopting AI and continuing to use data sets which contain historical bias. As institutes we can all be aware of this and start by looking at our data as well as the outputs we want. If we want diverse and inclusive outcomes, we must think of it as a process and create them from the start.
Diversity Comes in Many Forms
While racial and gender bias in AI is perhaps the most visible, diversity in AI encompasses far more than skin colour. It includes age, sexual orientation, disability, socioeconomic background, geography, culture, religion, and more. Each of these identities influences how people interact with technology and how technology responds to them.
For instance, older adults are often underrepresented in training data, leading to products that don’t meet their needs or recognise their usage patterns. People with disabilities face barriers due to a lack of accessible design. Most natural language processing tools perform best in English, marginalising billions who speak other languages. That’s why inclusive design needs to be part of AI development from the beginning not just as an afterthought. It means building with, not just for, diverse users. It requires inclusive datasets, diverse design teams, and actively checking for who is missing or misrepresented.
AI is already reinforcing narrow, exclusionary norms, unless we actively challenge this approach, we risk AI becoming a tool that doesn’t benefit the majority. Inclusive Ai means designing frameworks that recognise, respect, and reflect the full spectrum of human identity.
The AI Workforce Problem
Diversity issues in AI aren’t limited to datasets. They also stem from a lack of representation in the industry itself as AI development teams are predominantly white, male, and concentrated in North America and Europe. More than half of AI professors are men, while women make up a small fraction of AI research staff at some big tech firms, with less than 10% at some firms. The percentage is even lower for black employees at major tech firms, with just below 5% at giants such as Facebook and Microsoft . The absence of diverse voices in the design and decision-making process contributes to systems that overlook, misunderstand, or misrepresent underrepresented groups.
The lived experiences of developers deeply influence the systems they build. Without a variety of perspectives, it becomes easy to miss use cases, make assumptions about users, or perpetuate blind spots. To build inclusive AI, it’s important to have inclusive teams who can provide diverse perspective and bring diverse voices to the table, this will allow for them to be heard and visible in an AI empowered future.
Global and Cultural Gaps in AI
Most AI usage and development today is concentrated in the global north, especially in English speaking countries. This geographic concentration shapes how these systems are used, the data these systems are trained on as well as the perspectives they prioritise.
As a result, non-western cultures, languages, and identities are often underrepresented, oversimplified, or inaccurately portrayed. Language models can perform poorly with non-English text. Certain AI systems also struggle to
fluently mix languages in the same expression and context, investigations on ChatGPT, showed it performed substantially worse at answering factual questions or summarising complex text in non-English languages and was more likely to fabricate information.
Open AI’s report card on GPT-4, its most advanced language model, states that the majority of the underlying data came from English and that the company’s efforts to fine-tune and study the performance of the model primarily focused on English with a US-centric point of view. Beyond technical shortcomings, this imbalance can reinforce and sideline other worldviews.
Additionally, the ways we use AI and the innovations that come from the technology also risk being limited, there could be great new innovations and ideas that come from perspectives different to the majority or a niche. If those perspectives can be involved or have a seat at the table then we can find new ideas and solutions to problems both old and new.
For AI to be truly global, it must be built with global input recognising that cultural differences, context, language, and identity are not minor issues, but core to the fairness, functionality and equity of AI.
Inclusive AI in Action
Change is possible and it’s already happening in small but meaningful ways. Researchers, and technologists are working to solve these problems. There are open-source initiatives trying to build more representative datasets. Public projects are attempting to diversify the field, create accessibility and focus on marginalised when it comes to AI.
In practise, inclusive design in AI is about actively involving affected communities in how AI tools are built and used. Inclusive AI means AI that is designed, developed, and deployed with intentional awareness of human diversity across race, gender, age, ability, culture, language, geography, socioeconomic background, and more. It’s not just about avoiding bias or harm; it’s about actively including people who have historically been excluded or misrepresented by technology
What Needs to Change
To make AI truly inclusive, some ideas to consider centre around:
- Investing in diverse teams across the AI pipeline.
- Require transparency in datasets.
- Incorporate diversity and inclusion principles from the start.
- Expand training data to include marginalised communities.
- Promote regulatory frameworks that enforce fairness and accountability.
This technology is not impartial, it already has a point of view, and that point of view is what is has been trained on. If its missing marginalised or minority communities in its opinion, it’s because that opinion lacked in its data. It’s important to identify and rectify any bias early, understand who’s missing out or being overlooked. This can provide us with an opportunity to make sure the data we already have access to meets ethical and inclusivity standards. Being aware allow us to be aware of data blind spots and create fairer, more representative outcomes from AI systems.
A Call to Action
In summary, diversity in AI shouldn’t be optional, it should be foundational. It is already evident the lack of diversity early in the technology’s lifecycle. AI systems touch many lives, and they must be designed to uplift, not exclude. This requires confronting the biases we’ve inherited and embedding inclusion at every opportunity.
It all starts with awareness, creating inclusive AI is about recognising and respecting the full spectrum of human diversity. It’s built with representative data, shaped by diverse voices, and designed to serve people across race, gender, age, ability, language, and culture. Everyone should try to make sure no one is left out and that’s when we can have the best outputs from AI.
Find out more by visiting our Artificial Intelligence page to view publications and resources, join us for events and discover what AI has to offer through our range of interactive online demos.
For regular updates from the team sign up to our mailing list.
Get in touch with the team directly at AI@jisc.ac.uk