
As artificial intelligence (AI) becomes more deeply embedded in education, institutions face the crucial question of can we tell what has been produced by AI? This challenge isn’t just limited to academic integrity anymore; it extends to the transparency and accountability of all educational outputs.
Many in higher and further education will already be familiar with the difficulties of identifying students who have used AI in inappropriate ways in their assessments. While many institutions have adopted a more flexible assessment design that allows limited AI use, the need to distinguish between human and machine-generated content remains essential. Traditional detection tools, originally built to detect plagiarism and re-use of assessments, have offered a starting point for detecting inappropriate AI usage. However their accuracy is often inconsistent, and they can be circumvented easily with slight modifications to the text.
Beyond academia, there is a growing call to be able to differentiate human generated content from that generated by AI. From Deepfake images and video, to bot accounts infiltrating social media and spreading misinformation, one of the biggest issues with AI content has proved to be our inability to detect it.
That is why watermarking, a technique of embedding an invisible signature directly within AI models, is now gaining momentum. As Google prepares for the wider release of SynthID, its in-model watermarking technology, this is a good opportunity for institutions to explore how watermarking could be used across academia to improve trust and transparency when using AI.
We briefly explored watermarking in a 2023 blog post when development was just beginning. Now, two years on, it’s time to revisit the conversation. This post will only cover detecting AI-generated text, as this forms the bulk of issues within education. Over the coming months we will look to explore watermarking across other forms of media.
Trust beyond academia
While watermarking has clear benefits for managing academic integrity, its real potential lies in reinforcing trust in AI systems more broadly.
As AI-generated articles and research papers become more widespread, watermarking could help students and teachers verify whether the sources they’re referencing were human or machine-generated – giving greater confidence in the credibility of their work.
Consider a job application where a candidate’s cover letter appears flawlessly polished, how can an employer assess authenticity? Or a news article that seems too perfectly composed, can readers trust it wasn’t machine written?
In each case, watermarking offers a path to greater transparency and accountability. It doesn’t limit AI use, but it does provide a way to disclose and verify it. Proving to be essential as we navigate the ethical boundaries of AI in public life.
Institutions benefit from this too. If specific AI tools are endorsed internally, watermarking helps verify whether they were used appropriately, supporting policy enforcement without heavy oversight.
Why we’re talking about this now
We’re publishing this blog in anticipation of the wider release of SynthID, Google’s in-model watermarking technology. Originally launched to tag AI-generated images and videos, SynthID is now being piloted in Google’s Gemini, marking a significant step toward making watermarking a core feature of generative AI tools. By embedding a detectable signature at the point of content creation, SynthID could begin a shift in industry thinking; from reactive detection to proactive responsibility.
Google currently leads the way with this approach, having also open-sourced SynthID, enabling smaller AI developers to build watermarking into their own systems. Although it’s still in limited release via an early testers waitlist, SynthID is expected to become more broadly available in the coming months.
Other companies have been also exploring watermarking, albeit at different stages. OpenAI has worked on developing watermarking methods for its ChatGPT models, but has paused rollout due to concerns over evasion tactics and the risk of users migrating to non-watermarked competitors. They report that they’re also investigating alternative safeguards.
Anthropic, the maker of Claude, has reported that watermarking is on their roadmap, but remains in the research and development phase.
If SynthID proves to be a useful tool, this could be the push needed for other companies to work to release watermarks for their own models and the beginning of this becoming an industry standard.
How watermarking models work

Though they share a name, AI watermarking is very different to traditional watermarks. While a traditional watermark is effective at showing ownership of an image, it is usually trivial to remove or crop out of the final product. Additionally, as there is a big signature across the work, they affect the quality of the output.
In contrast, AI watermarking aims to create a signature across the text that is only detectable through a dedicated detection tool and does not alter the quality of the output.
To understand the effectiveness of watermarking, it helps to first grasp how AI language models generate text.
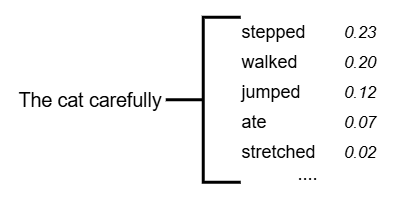
Models like ChatGPT generate sentences by analysing the words already provided and predicting the most likely next word from a vast set of possibilities. Each possible next word has a calculated probability based on the previous words and patterns learned from extensive training on large datasets.
As this prediction process continues, each chosen word becomes part of the new context for predicting the next words, creating coherent and contextually relevant content.

When a watermark is used, the model uses a pseudorandom function that hashes the previous few words to produce a random number – We will call this the seed. In layman’s terms, this means that the tool looks at the last few words it generated and scrambles them using a secret formula, the output from this being an effectively random number.
Importantly, a Private Key – A very long, secret string of random numbers – is added to the words when creating the seed. This is only known to the company producing the watermark, stopping reverse engineering. Because the seed is tied to the context of the previous words, the same words will always yield the same number, yet outsiders who don’t know the key cannot predict it.

The seed is then used to divide all possible next words into 2 groups. To those who don’t have the key, this appears to be a completely random split of words.
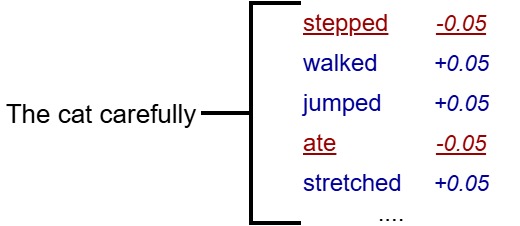
Words from Group 1 get a slight increase in their likelihood of being chosen as the next word, while those from Group 2 get a slight decrease. This adjustment is only slight, and therefore unlikely to decrease the quality of the output. However, over multiple word predictions, this subtle adjustment creates a statistical watermark.

The model applies this adjustment throughout the entire generated text.

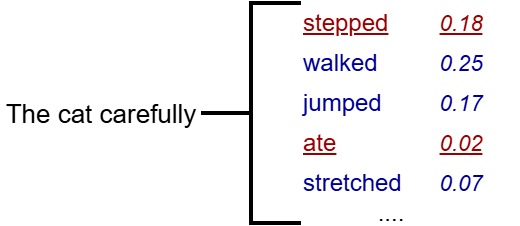
To detect this watermark, a verification tool, armed with the same secret key, rehashes the text and recreates the Group 1 / Group 2 splits for each position. The ratio of group 1 to group 2 words is then measured.
Naturally written content typically would show an even balance between these groups, whereas AI-generated, watermarked texts have a significantly higher proportion of Group 1 words, indicating artificial creation.
To note:
- Because each part of a document can be tested independently, reviewers can zoom in on a single paragraph, chapter, or submission to see where AI assistance likely began.
- The larger the sample tested, the clearer the watermark signal, so reliability rises with excerpt length.
- Detectors are able to output a numerical confidence score, helping staff judge how much weight to give the result before deciding on any further academic-misconduct action.
Please note that each individual model implements watermarking slightly differently. These images are purely demonstrative; they do not represent actual watermark implementations.
Why watermarking is preferable to detectors
Traditional detectors rely heavily on identifying statistical anomalies, linguistic patterns, or stylistic signatures which AI models are more likely to use compared to human produced content. However, savvy students can circumvent this through simple rephrasing, paraphrasing tools, or minor edits to the text. Because watermarking happens during the content-generation stage itself, the embedded signals are more resistant to edits and transformations, ensuring a more robust layer of reliability and protection against attempts at evasion.
Additionally, traditional detectors are more likely to flag false positives, particularly for students who don’t speak English as a first language or are Neurodiverse. As watermarking is not based around sentence structure or Tonal choices, they will be less biased towards specific writing styles. This safeguards students’ reputations and ensures that institutional resources are spent on substantiated cases rather than unwarranted investigations.
AI developers are introducing watermarks for two key reasons.
- To prove responsible, ethical practice – A visible commitment to watermarking shows institutions and regulators that the company can trace and verify its own output, aligning with emerging standards for trustworthy AI.
- To protect future model quality – By tagging their own content, developers can filter it out of the data they use for further training, preventing a feedback loop of AI-generated text that would otherwise dilute accuracy and originality.
Benefits for your institution
Stronger Proof – Watermarks provide more conclusive evidence of AI-generated content, which is especially beneficial for handling academic integrity cases.
Harder to Avoid – Watermarking is more resistant to minor text changes and rephrasing, giving your institution stronger control over AI use.
Institution specific Policies – If your institution endorses specific AI models, watermarking can help clearly identify approved versus non-approved AI-generated content.
Limitations and issues
Difficulties with Factual Text – Because the alterations of the probabilities are only slight, text with minimal linguistic variation, like highly factual reports, is harder to watermark reliably.
Switching models – Even if most models implement watermarks, there will always be a market for non-watermarked models. Open-source models are also readily available with a little technical know-how, versions where the watermark has been stripped away would mean even a legal mandate wouldn’t be effective.
Access
Right now, no one knows how, or at what price, universities will be able to use watermark-detection tools. The companies behind them could offer a free website or plug-in that staff can open with a few clicks, or they might license the technology to services such as Turnitin and charge a fee. They could also keep it behind a premium contract that only larger institutions can afford.
If the tool is too easy to access, a user trying to pass off AI content as their own could simply keep tweaking their work and testing it until the watermark disappears. AI firms will have to find a middle ground – letting staff use the detector without hassle while stopping repeated, anonymous checks, perhaps by asking users to log in or capping the number of tests.
Next steps for institutions
Watermarking is emerging as a promising step toward greater trust and transparency in the use of AI. While it won’t solve every challenge, it can provide institutions with a more dependable way to identify AI-generated content and support responsible use.
When it’s made available it should be treated as one part of your academic-integrity toolkit that also includes refreshed assessment designs and clear guidance for staff and students. For now, we recommend institutions keep a watchful eye on the technology to see how it develops. As adoption increases, Jisc will continue to update AI literacy training and resources to help staff and students incorporate watermarking checks and verify authorship of work.
Ultimately, no single safeguard can replace human judgment. The ability to critically assess the value and authenticity of content remains essential. Educators should be proactive in building their own AI literacy so they can confidently guide students, evaluate the credibility of AI-assisted work, and help shape policy. The more teachers understand AI’s capabilities and limitations, the better equipped we will be to foster a culture of transparency, responsibility, and trust in classrooms and beyond.
Find out more by visiting our Artificial Intelligence page to view publications and resources, join us for events and discover what AI has to offer through our range of interactive online demos.
For regular updates from the team sign up to our mailing list.
Get in touch with the team directly at AI@jisc.ac.uk