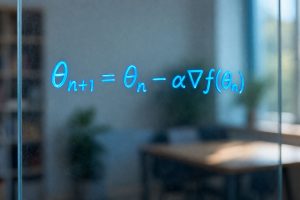
In my current role, I support universities and colleges as they explore the use of artificial intelligence in education. Much of this work focuses on how AI tools are applied in practice and on how institutions make sense of their opportunities and limitations.
Alongside this applied work, I have been developing a more foundational understanding of how AI systems work. This interest reflects a convergence of my current role and my earlier career as a maths and science teacher, where working with mathematical models, equations and abstract ideas was routine (and invigorating). While I am not developing AI tools professionally, I have found it useful to understand how they are constructed at an underlying level.
For me, this has meant returning to the fundamentals and engaging directly with the mathematics that underpins AI. This is not something my role requires, nor something I would expect others in the sector to do necessarily, but it aligns with how I have always learned most effectively – and is something I’ve found immensely rewarding.
Over the past year or so, I’ve been building small “DIY” projects to make core AI ideas feel concrete. One example was building a DIY linear regression model. I avoided pre-packaged python libraries so that I could trace every result back to lines of code I had written.
For linear regression, I started with a simple example: predicting someone’s weight from their height. Imagine a small dataset made up of pairs of numbers — height (X) and weight (Y). If you plot those points on a graph, they form a rough upward trend. A straight line can capture that trend using the equation:
Y = M X + C
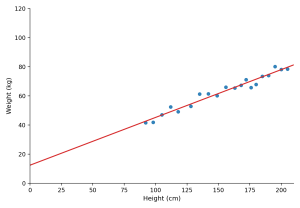
Here, M controls how steep the line is (how much weight changes as height increases), and C controls where the line starts on the vertical axis. (Someone with a height of 0 units, should theoretically weigh nothing, so we might expect C to be 0 in this case – if our equation truly reflects the data, that is).
The challenge is choosing values for M and C so that, across all the data points, the predicted weights (those outputted when you take each observed height in turn, multiply it by M and then add C to the result) are as close as possible to the real weights.
Because the line won’t pass exactly through every point, we need a way to measure how far off we are overall: how much error there is.
That’s where RMSE (Root Mean Squared Error) comes in. In simple terms:
- For each person, calculate the difference between the predicted weight and the real weight
- Square that difference so negative and positive errors don’t cancel out (if you predict one person’s weight to be 1kg greater than it actually is, and another’s to be 1kg less – you still want to capture that you’re out by 1kg both times – even if the net error becomes zero).
- Take the average of all those squared differences
- Take the square root so the error is measured in the same units as the variable (in this case, weight)
You can think of RMSE as the typical size of your mistake. If the RMSE is 3 kg, then your predictions are usually about 3 kg off.
To reduce that error, I used gradient descent. Instead of trying to calculate the perfect values for M and C in one step, gradient descent improves them gradually.
In plain terms, the process is:
- Start with some initial guesses for M and C
- Use them to predict weights based on heights (take each observed height in turn, multiply it by M, and then add C)
- Calculate how wrong those predictions are based on the actual observed weights (use RMSE as your measure of wrongness)
- Slightly adjust M and C in the direction that reduces the overall error (this step involves a bit of calculus, which I won’t go into here)
- Repeat.
Each adjustment is small and controlled by a setting called the learning rate, which determines how much you change the values of M and C each time. Too big a change, and you overshoot. Too small, and it takes a long time to reach the values of M and C that minimise the overall error.
In code, this becomes a clear set of instructions:
First, pick starting values for M and C
Then repeat the following steps until termination condition met (see below):
- Calculate predicted weights
- Calculate the overall error between predicted weights and actual weights
- Update M and C, based on learning rate (a value you choose) and a direction vector (you can write the code to calculate this, which requires knowledge of the calculus of gradient descent)
- Repeat, only stopping when the error stops reducing (i.e. you’ve reached the bottom of the hill, the equation’s minimum value for error, and now you’re moving up again) or after a set number of steps
Working in this way has helped ground some of the language that surrounds AI. Terms such as model, algorithm and training often sound abstract, but when you implement even a very simple version yourself, they can start to feel like straightforward ideas.
A model produces an output from an input, just like a mathematical equation.
Training involves repeatedly adjusting that model (e.g. changing the coefficients of the equation), so its outputs/predictions are closer to the data that has actually been observed.
Performance is measured relative to how wrong the model is compared to these observed data points. The smaller the error, the better the fit. The metric for error is often RMSE.
Seeing this process unfold explicitly reinforces that AI systems are not operating independently. They are carrying out mathematical procedures that have been carefully crafted and specified.
This perspective has been useful in my professional work. It makes it easier to interpret claims about AI capability, to recognise where AI tools are well-suited to particular tasks, and to remain cautious about generalisations. It also provides a practical reminder that AI systems embed choices made by their designers, rather than neutral or universal forms of intelligence.
None of this implies that engaging with code or mathematics is a necessary part of working with AI in education. However, recognising that AI is built from familiar mathematical ideas can help reduce the sense that it exists beyond ordinary understanding.
At the same time, it is important to recognise the limits of this kind of understanding. Many of the AI systems people interact with today, particularly large language models built on transformer architectures, are vastly more complex than the examples described here. They involve millions or billions of parameters, are trained on enormous datasets, and exhibit behaviours that are difficult to predict or fully explain, even by their creators.
Understanding basic principles does not dissolve that complexity. What it can do, however, is provide a frame of reference. It helps situate contemporary AI systems as extensions of earlier approaches, rather than as a complete break from them. It also clarifies that, however complex the system, it is still built upon mathematical principles, not science fiction (or magic).
At a time when AI is often framed in extraordinary terms, returning to first principles has helped me stay oriented. Working back through the mathematics cuts through much of the hype and brings the technology back into focus as something structured, designed and to some extent understandable. For someone who has always made sense of the world through mathematical ideas, that grounding has been both fascinating and reassuring.
Find out more by visiting our Artificial Intelligence page to explore publications and resources, learn more about our communities and sign up for our AI Literacy training.
For regular updates from the team sign up to our mailing list.
Get in touch with the team directly at AI@jisc.ac.uk